


This document talks more deeply about the ezop system architecture, both about its anatomy and implementation.
Written by Michal Krause (author), Tomas Znamenacek (translation into English).
Published on 7. 9. 2001.

index > documentation > Architecture overview
 Main information flow schema:
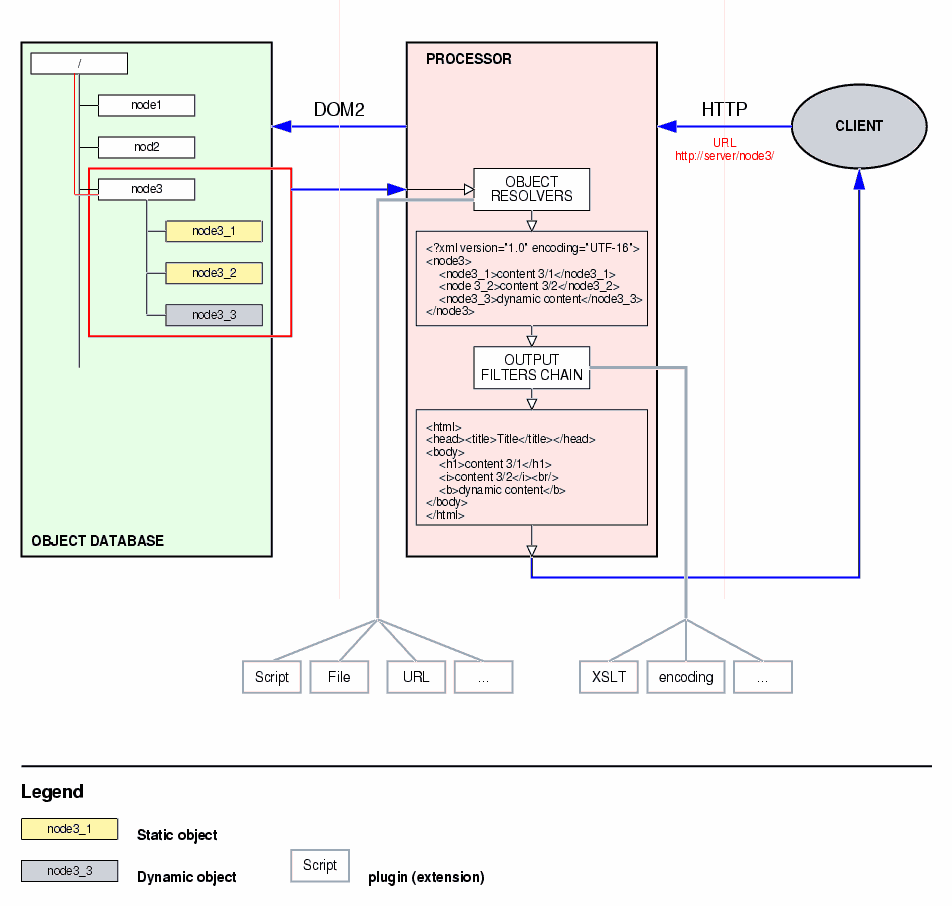
This schema shows the basic data flow inside Ezop.
Main information flow schema:
This schema shows the basic data flow inside Ezop.
Ezop is based on four crucial standards — HTTP, DOM, XSLT and UTF-16. HTTP represents the external interface for client-server communication, the data are internally represented by a DOM tree and the resulting document is formed by (possibly more than one) transformation using XSLT. The only internal character coding of the system is UTF-16.
This approach leads to complete separation of the document formatting properties and its content, thus allowing you to easily manage your web applications for long time periods even in bigger teams. It is also important to separate the last document part: the document logic — scripts, database connections etc.
As stated above, the data are represented by a DOM tree. The URL of the client request sent using HTTP protocol is mapped directly into this tree. The result of this request is a new DOM tree, the last part of requested URL being the root of this tree.
A simple static-data transformation clearly doesn't satisfy all the needs, to do this the new DOM tree is passed throught the object resolving process. Every object in the tree has got an attribute containing information about the data the object holds. Static objects contain plain text, that needs no transformation at all. On the contrary, dynamic objects contain some meta-data that need further processing. This processing is made by a resolver — a module that understands the input data and is able to generate some (input related) output data. The whole resolving process is executed recursively, because the resolver doesn't have to generate plain text (or other "low structure information" data), but also a whole branch of a tree, containing another static and/or dynamic content.
After the object resolving process, the DOM tree contains the final version of the document content — the version that is being sent to the client. But this data have got no formatting applied or linked so far — this is added by (possibly more than one) output filter. Every output filter is one of the following kind:
The primary transformation filter is a XSLT processor transforming a DOM tree into XML document (or some its application like WML and XHTML), HTML etc. Other transformation filters can take care of the non-text output, generating PDF files, for example. Other filters can take of the character set conversion, data compression etc. If there is no filter assigned with the output, the resulting document is XML in the UTF-16 encoding.
The access to the DOM tree nodes — objects — is controlled via ACL. The URL -> DOM tree mapping requires going through all the nodes on the way from root node to requested node, this means easy implementation of the access rights inheritancy. The user authentication is realized via the HTTP protocol, unknown user has got either no rights or the rights to view the public part of the DOM tree only.
The system provides easy fulltext and field based indexing and searching. Indexes are updated on the fly — they are updated each time an "insert into the DOM tree" operation executes.
The main engine consist of multi-threaded core implementing the interface between backend (an object database), object resolvers, output filters, client (HTTP protocol) and the caching engine. The main core task is to create a kind of bus and provide its API to other system components while keeping everything as simple as can be. Every transformation, object resolving etc. happens outside the engine in its own module.
Object resolvers are dynamically loaded modules with consistent API. Every resolver tells the system which kind of object it's able to work with (a kind of "content-type"). Basic resolvers are script (a chunk of code in a selected scripting language), URL (a request for including an external document), file (a redirection to filesystem, mainly because of pictures and other binary data) and link (surprisingly a link to other part of the tree, great for virtual branch construction — the articles written by certain author can form a virtual branch, while physically being a part of the "cathegory" branch). Above other data, the resolver can also output meta-data, telling the system about caching, expiration time etc.
The recursion provides an easy way to apply more resolvers on one node — for example, using an URL resolver You can import an article list from some other server (in the RSS format) and parse it by other resolver into full-featured tree branch.
The output filters are dynamically loaded modules, just as the object resolvers. Every filter tells the system where it desires to be placed — DOM tree parsing, the raw data parsing or the place between. The "between" filter can be used only once per a "stream" (meaning the filter transformation stream from the DOM tree into final raw data), however You can have as many these filters in the whole system as You wish. There can be more "DOM tree -> DOM tree" and "raw data -> raw data" filters in one transformation stream, every filter can be even called more then once in one transformation.
The script object resolver is going to interprete selected language, the SpiderMonkey JavaScript implementation from the Mozilla project seems to be a good candidate. Its pro's are mainly language simplicity, both object and procedural model, well-known syntax, full Unicode support, the ability to compile into bytecode, the ability to run the scripts in separated context, good extensibility and last (but not least) the promise of continuing progress (as it is a part of Mozilla).
index > documentation > Architecture overview



{kind=link}